우선, 전통적인 RDB의 Index와 차이를 알아야 합니다.
전통적인 관계형 DBMS에서 Index는 테이블의 record당 하나의 항목을 포함합니다. 곧 record 수 만큼의 항목을 포함하는 Index가 됩니다. 이런 Index를 B-Tree 알고리즘을 통해 특정 행을 빠르게 찾게 되므로 조회 및 업데이트 의 효율성을 높입니다.
이에 반해 ClickHouse는 대용량 데이터를 처리하도록 설계되었기 때문에 전혀 다른 방식을 사용하여 Index를 운용합니다. 매우 큰 규모를 다루기 때문에 Disk 및 Memory 효율성이 최우선으로 고려됩니다. 이에 따라 모든 record를 Indexing하지 않고, record를 Block으로 나누어 Block 당 하나의 Index로 운용 합니다. (이하 Sparse Index)
따라서 B-Tree Index 처럼 특정 record를 찾는 방식이 아닌, 특정 record가 속한 데이터 Block을 찾는 방식으로 Index를 운용 합니다. Sparse Index 방식은 ClickHouse에서 데이터를 저장할 때 이미 PK 기준으로 물리적 정렬 상태를 갖기 때문에 가능해집니다.
Sparse Index 동작 방식

위와 같은 Table을 Create 할 때, 해당 Table은 Order By (정렬 키)에 따라 데이터가 물리적으로 정렬되어 저장됩니다 (정렬 키의 순서대로 오름차순 정렬되어 디스크에 저장).
이는 비슷한 또는 같은 값을 갖는 데이터가 물리적으로 붙어 있을 수록 압축의 효율이 상승하기 때문입니다. 이 때 Primary Key를 별도로 설정하지 않으면, 자동적으로 Order by에 사용된 정렬 키를 PK로 설정하여 Primary Index를 생성합니다.
위와 같은 Create 문으로 Table이 생성 된 후, 데이터가 삽입되면 아래와 같은 데이터 구조(그림 1.1)를 갖게 되며, Click House에서는 이 데이터를 granularity 크기(8192)로 데이터를 묶습니다. (그림 1.2)
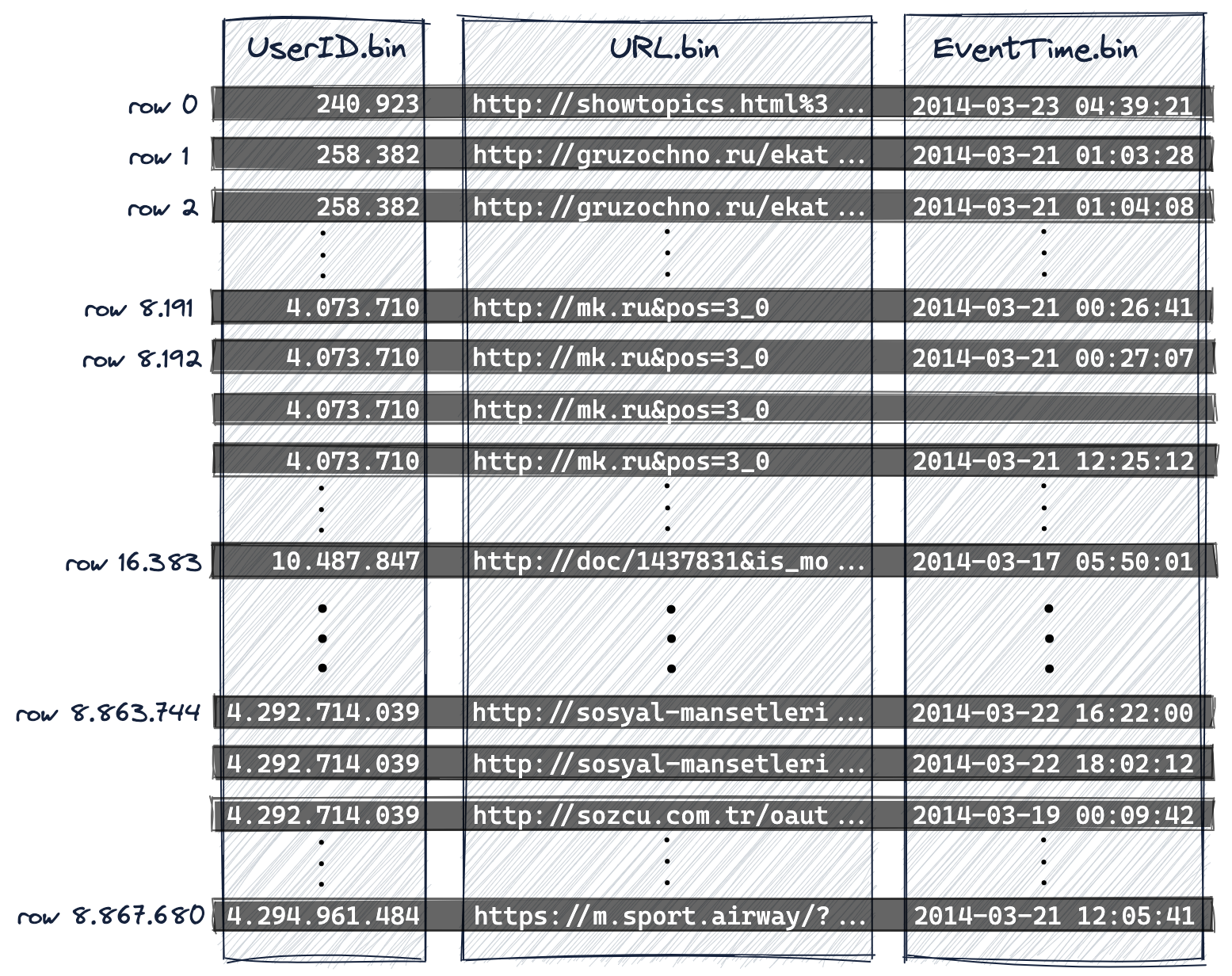

그림 1.2) 에서 볼 수 있듯이 약 886만 record가 존재하는 raw data를 8192 record를 한 묶음으로, 총 1083개의 granule block이 생긴 것을 확인할 수 있습니다.
ClickHouse에서는 각 granule를 0번부터 숫자를 붙이고, 이 block들의 묶음을 idx 파일을 통해 관리를 합니다. idx 파일은 아래 그림과 같이 각 granule block의 첫 번째 record의 PK 값을 갖습니다. idx 파일에서 pk column의 값으로 이뤄진 한 record를 mark 라고 부릅니다. (granule과 1:1 match)

ClickHouse에 쿼리가 수행될 경우, 이진 탐색(Binary Search)을 통해 idx 파일을 검색하게 됩니다. 예를 들어, WHERE UserID = 3,903,231 이라는 조건으로 Index를 탐색하게 될 경우 3,903,231이라는 UserID 값은 idx 파일에서 mark1의 UserID보다 작고, mark0의 UserID보다 큰 값이니, granule 0 블록에 존재한다는 사실을 알게 됩니다.
여기까지가 ClickHouse가 쿼리와 일치하는 record를 포함하는 Data Block을 찾는 과정입니다. 이제 찾아낸 Data Block에서 실제로 일치하는 record를 찾기 위한 과정에 대해 설명 하겠습니다.
Table이 생성되면, ClickHouse는 데이터의 압축 파일인 .bin, Index 파일인 .idx, 마지막으로 Index를 통해 데이터의 물리적 위치를 찾아가는 .mkr3 파일을 생성합니다. 아래는 mrk3 파일의 내부 구조입니다.

이 mrk3 파일은 두 가지 값을 갖고 있습니다.
1. 압축된 데이터인 bin 파일에서 각 granule block들의 Offset(물리적 위치)
2. 압축 해제된 raw data 안에서 granule block들의 Offset

ClickHouse는 raw data를 압축해서 갖고 있기 때문에 압축 방식에 따라 데이터의 위치가 조금씩 다를 수 있습니다. 따라서 위 그림의 과정을 통해 압축된 파일에서 각 granule의 위치(Offset)를 mrk 파일로부터 받아 압축된 데이터 블록을 가져옵니다.
해당 압축 data 블록을 압축 해제하고 나면, 그 안에서 쿼리에 부합하는 granule의 Offset을 mrk 파일로부터 받아 실제 granule에 접근할 수 있게 됩니다. 이렇게 찾은 granule, 실제 데이터는 clickhouse가 사용하는 Mem- ory로 Streaming하여 올리게 됩니다.
위와 같은 과정을 간단하게 도식화 하면 아래와 같은 그림이 됩니다.

이상의 내용이 PK로 지정한 (기본 키, 명시하지 않은 경우 정렬 키) column에 대해 기본적으로 생성되는 primary index와 ClickHouse의 index 동작 방식에 대한 설명이었습니다.
Primary index와 별개로 특정 column에 대한 index에 대해서는 내용이 길어 다음 번 자료에 공유하겠습니다.
참조 ) https://clickhouse.com/docs/en/optimize/sparse-primary-indexes
참조 ) https://clickhouse.com/blog/clickhouse-faster-queries-with-projections-and-primary-indexes
'오픈소스 > ClickHouse' 카테고리의 다른 글
| [ClickHouse] INDEX 구조와 동작 원리 - ③ (0) | 2023.07.06 |
|---|---|
| [ClickHouse] INDEX 구조와 동작 원리 - ② (0) | 2023.07.06 |
| [ClickHouse] Data 구조 (0) | 2023.06.30 |
| [ClickHouse] Shard & Replica 개념 (0) | 2023.06.14 |
| Click House 개요 (0) | 2023.06.14 |



